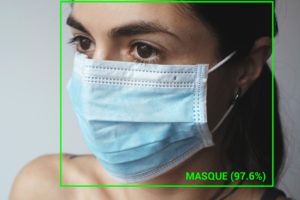
La detección de objetos en visión artificial utiliza aprendizaje profundo , que comprende una familia de modelos de aprendizaje automático descritos como redes neuronales organizadas en capas. Generalmente, todos los modelos de aprendizaje supervisado utilizados para la detección de objetos en una imagen son redes neuronales artificiales empleadas para el aprendizaje profundo.
El aprendizaje profundo puede ser supervisado o no supervisado, según la situación. En este artículo, nos centraremos únicamente en el aprendizaje supervisado. En este caso, los datos utilizados están etiquetados, es decir, conocemos el resultado que el modelo debe obtener. Esto se aplica a cada ejemplo utilizado durante el entrenamiento. El objetivo final es aprender a asociar cada ejemplo con la etiqueta correcta.
Dediquemos unos minutos a repasar los principios fundamentales del aprendizaje profundo supervisado para la detección de objetos. Cabe destacar que he evitado entrar en una descripción matemática del aprendizaje profundo. Por lo tanto, este artículo está pensado para ser accesible a todo el mundo.

Aprendizaje profundo supervisado para la detección de objetos en visión por computadora
Principios generales de detección de objetos en visión por computadora
Una red neuronal artificial es un modelo de aprendizaje automático compuesto por unidades de cómputo llamadas neuronas. Una neurona calcula una suma ponderada de las entradas y aplica una función no lineal al resultado de esta suma. Esta es la función de activación , que analizaremos más adelante.
Con frecuencia, la salida de una neurona se introduce en la entrada de una o más neuronas (dependiendo del número de capas), hasta llegar a la salida de la red. En ocasiones, también se puede utilizar una red neuronal recurrente. En este caso, la salida de una neurona se puede usar como entrada de esa misma neurona.
El entrenamiento de una red neuronal implica optimizar la ponderación de cada suma. Estas ponderaciones se convierten en los parámetros de la red. Para optimizar las ponderaciones, se utiliza un algoritmo de retropropagación para minimizar el error entre la predicción y la etiqueta de entrada.
Funcionamiento de una neurona
Al igual que una neurona biológica, una neurona artificial recibe señales de entrada de otras neuronas. Las sinapsis se modelan mediante pesos asignados a los valores de entrada.
Las neuronas no siempre están activas. Un valor de ponderación alto provoca la excitación de la neurona. Por el contrario, si la ponderación es negativa, la entrada tendrá un efecto inhibitorio. Si la suma ponderada de estas entradas supera un cierto umbral, la neurona se activa. La función de activación determina este umbral. El resultado de la función de activación se transmite a las neuronas subsiguientes.
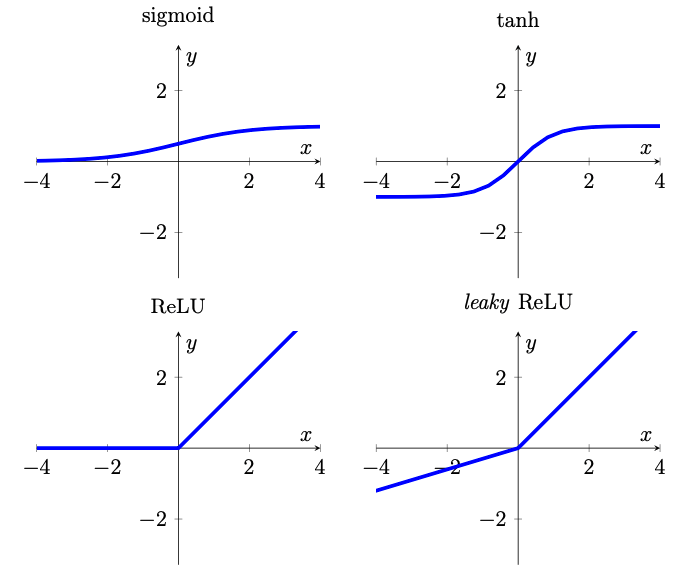
Sin entrar en detalles, aquí están las cuatro funciones de activación principales. La pendiente de la ReLU con fugas se ha exagerado para mayor claridad (de [1]).
Redes neuronales convolucionales
Al analizar una imagen, las propiedades que se introducen en la red neuronal son los valores de intensidad de cada píxel. En una imagen RGB, existen tres intensidades para cada color: rojo, verde y azul.
En este caso, para evitar problemas de memoria debido al gran tamaño de la imagen y la cantidad de parámetros a procesar, podemos usar una red más pequeña. Cada píxel se procesa individualmente mediante convoluciones . Estas convoluciones se utilizan para crear mapas de propiedades . Esto se puede visualizar como imágenes multicapa: cada capa representa una propiedad obtenida mediante un filtro de convolución .
Los mapas de propiedades son de tamaño reducido y pueden ser procesados por una red totalmente conectada sin limitaciones de memoria. Este tipo de modelo se denomina red neuronal convolucional ( CNN ).
Convoluciones
Cuando una CNN procesa una nueva imagen, desconoce qué características contiene o dónde se ubican. Por lo tanto, estas redes intentan determinar si una característica está presente en la imagen mediante filtrado. Las operaciones matemáticas utilizadas se denominan convoluciones. Al procesar una imagen, la posición de cada píxel es fundamental. Esto es una ventaja, ya que esta información la utiliza una capa convolucional.
La ventana de convolución (o núcleo) es una matriz pequeña, generalmente cuadrada. Su tamaño se fija durante el diseño de la red y suele ser de 3×3. Esta ventana se desplaza sobre el mapa de propiedades. En cada posición, se calcula el producto término a término entre la ventana de convolución y la porción del mapa de propiedades en la que se encuentra (véase la ilustración a continuación). Finalmente, se aplica una función no lineal a la suma de los elementos de la matriz resultante.
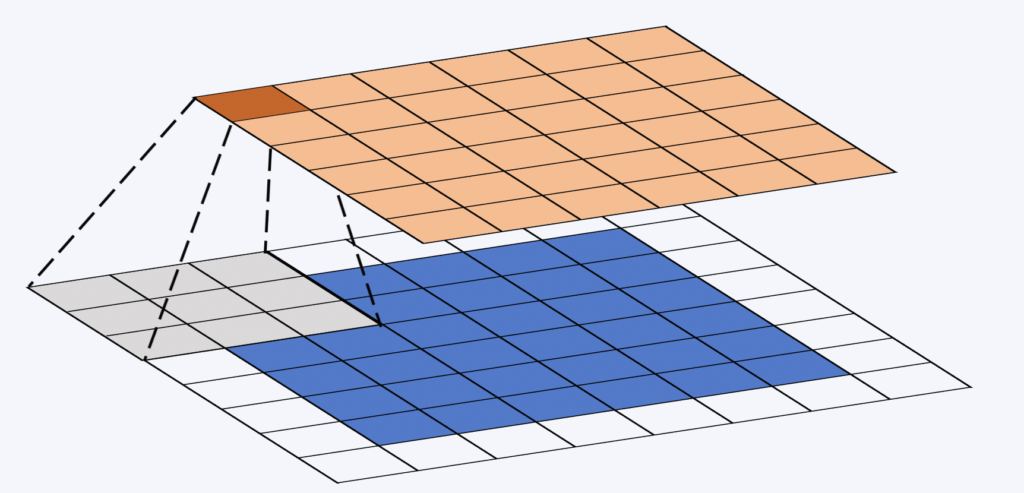
Durante el proceso de convolución, los pesos permanecen invariables. Así es como podemos aprovechar la potencia de cálculo de las GPU modernas .
Agrupación
El pooling es un método para tomar una imagen y reducir su tamaño conservando la información más importante que contiene.
La forma más común se denomina Max-Pooling, que consiste en arrastrar una pequeña ventana sobre toda la imagen y tomar el valor máximo de esta ventana en cada paso. Normalmente se trata de una ventana/matriz de 2×2 (véase la ilustración a continuación).
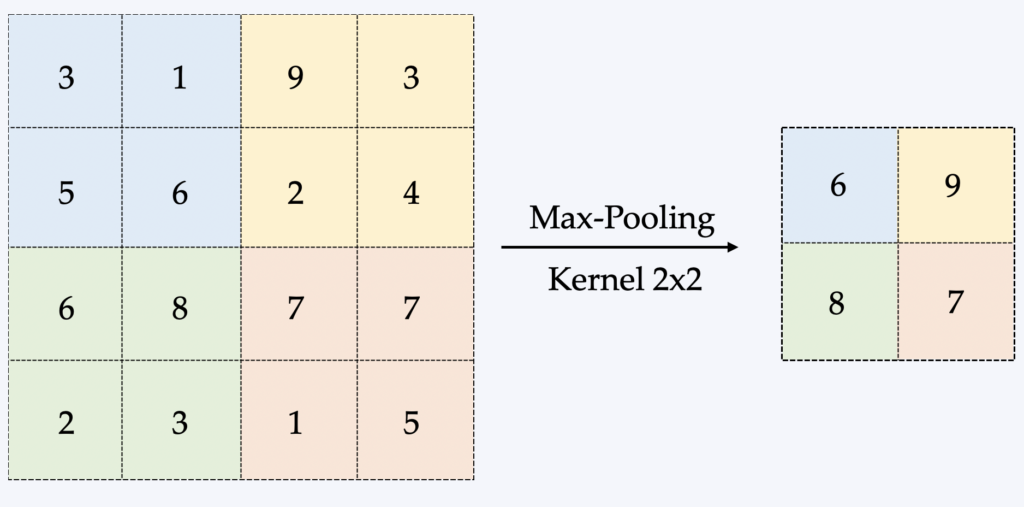
La principal ventaja del pooling es, por lo tanto, reducir el tamaño de los datos procesados en memoria, un factor limitante en el entrenamiento de CNN. La retropropagación se ve afectada de forma diferente según el método de pooling, pero no entraremos en detalles aquí.
Campos receptivos
El campo receptivo se refiere a la región de la imagen que se introduce en la red. Ampliar el campo receptivo proporciona más contexto para clasificar una ubicación. Esto también permitirá detectar objetos de mayor tamaño dentro de una imagen.
La agrupación es un método para aumentar el campo receptivo de una neurona. La función de activación también modifica este campo efectivo, y podríamos tratar este tema en un artículo futuro.
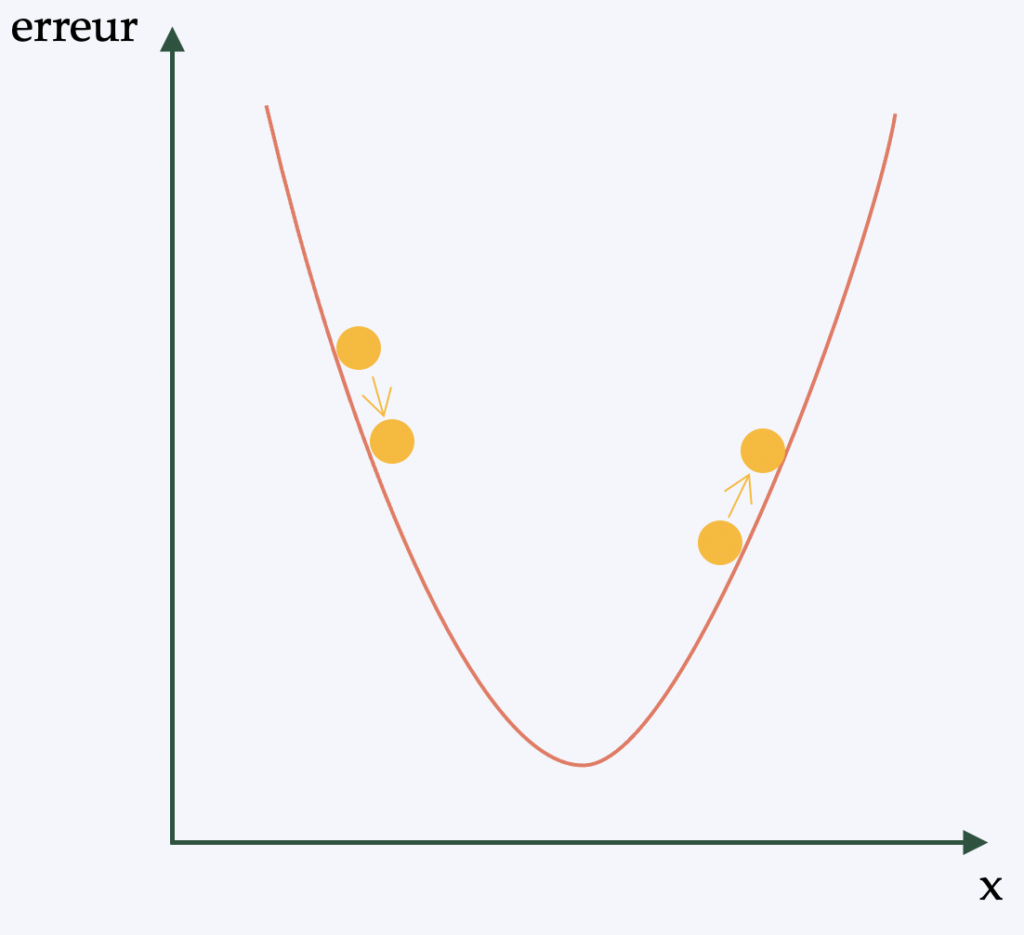
retropropagación
En pocas palabras (y para evitar una descripción matemática compleja), la retropropagación es el algoritmo que se utiliza para aplicar la estrategia de aprendizaje a los pesos de la red neuronal. El objetivo es poder aplicar una forma de descenso de gradiente ( un algoritmo de optimización diferenciable ) a la red.
De hecho, Para cada imagen analizada por la CNN, se obtiene una puntuación. El número de errores cometidos en la clasificación/detección indica la calidad de las características y los pesos. A continuación, se ajustan las características y los pesos para reducir el error, y este es el proceso de aprendizaje. Independientemente del ajuste realizado, si el error disminuye, se mantiene el ajuste. Este proceso se repite con cada una de las demás imágenes etiquetadas.
Obtén más información sobre el aprendizaje profundo supervisado para la detección de objetos en visión por computadora.
En este artículo hemos descrito de forma sencilla los principales principios del aprendizaje profundo supervisado para la detección de objetos en visión por computadora.
Si desea incorporar IA a su proyecto de visión artificial, contáctenos y pondremos toda nuestra experiencia a su disposición. Gestionamos la creación del conjunto de datos ( base de datos ), lo cual representa un proyecto de gran envergadura. Podemos crear una base de datos extensa a partir de imágenes o vídeos (con varios miles de imágenes anotadas). Posteriormente, entrenamos un modelo seleccionando la arquitectura y la metodología de red neuronal adecuadas .
En el próximo artículo, presentaremos un ejemplo concreto de un modelo de detección de objetos desarrollado por Imosolia. ¡Estén atentos!