Die Objekterkennung in der Computer Vision nutzt Deep Learning , eine Familie von Modellen des maschinellen Lernens, die als neuronale Netze in Schichten organisiert sind. Im Allgemeinen handelt es sich bei allen überwachten Lernmodellen, die zur Objekterkennung in einem Bild verwendet werden, um künstliche neuronale Netze, die für Deep Learning eingesetzt werden.
Deep Learning kann je nach Situation überwacht oder unüberwacht erfolgen. Im Folgenden befassen wir uns ausschließlich mit überwachtem Lernen. Hierbei sind die für das überwachte Lernen verwendeten Daten bereits gelabelt. Das heißt, wir kennen das Ergebnis, das das Modell erzielen soll. Dies gilt für jedes einzelne Trainingsbeispiel. Das Ziel ist es, jedem Beispiel das korrekte Label zuzuordnen.
Nehmen Sie sich ein paar Minuten Zeit, um die grundlegenden Prinzipien des überwachten Deep Learning für die Objekterkennung zu erläutern! Ich habe bewusst auf eine mathematische Beschreibung des Deep Learning verzichtet. Dieser Artikel soll daher für jeden verständlich sein.

Überwachtes Deep Learning zur Objekterkennung in der Computer Vision
Allgemeine Prinzipien der Objekterkennung in der Computer Vision
Ein künstliches neuronales Netzwerk ist ein Modell des maschinellen Lernens, das aus Recheneinheiten, sogenannten Neuronen, besteht. Ein Neuron berechnet eine gewichtete Summe der Eingaben und wendet auf das Ergebnis dieser Summe eine nichtlineare Funktion an. Dies ist die Aktivierungsfunktion , die wir später genauer betrachten werden.
Oft wird der Output eines Neurons als Input für ein oder mehrere Neuronen (abhängig von der Anzahl der Schichten) verwendet, bis er den Output des Netzwerks erreicht. Manchmal kommt auch ein rekurrentes neuronales Netzwerk zum Einsatz. In diesem Fall kann der Output eines Neurons als Input für dasselbe Neuron verwendet werden.
Das Training eines neuronalen Netzes beinhaltet die Optimierung der Gewichtung jeder Summe. Diese Gewichte werden dann zu den Parametern des Netzes. Zur Optimierung der Gewichte wird ein Backpropagation- Algorithmus verwendet, um den Fehler zwischen der Vorhersage und der Eingabebezeichnung zu minimieren.
Funktionsweise eines Neurons
Ähnlich wie ein biologisches Neuron empfängt ein künstliches Neuron Eingangssignale von anderen Neuronen. Synapsen werden durch Gewichtungen modelliert, die den Eingangswerten zugewiesen werden.
Neuronen sind nicht immer aktiv. Ein hoher Gewichtungswert führt zur Erregung des Neurons. Umgekehrt hat ein negativer Gewichtungswert eine hemmende Wirkung. Überschreitet die gewichtete Summe dieser Eingänge einen bestimmten Schwellenwert, wird das Neuron aktiviert. Die Aktivierungsfunktion bestimmt diesen Schwellenwert. Das Ergebnis der Aktivierungsfunktion wird dann an nachfolgende Neuronen weitergeleitet.
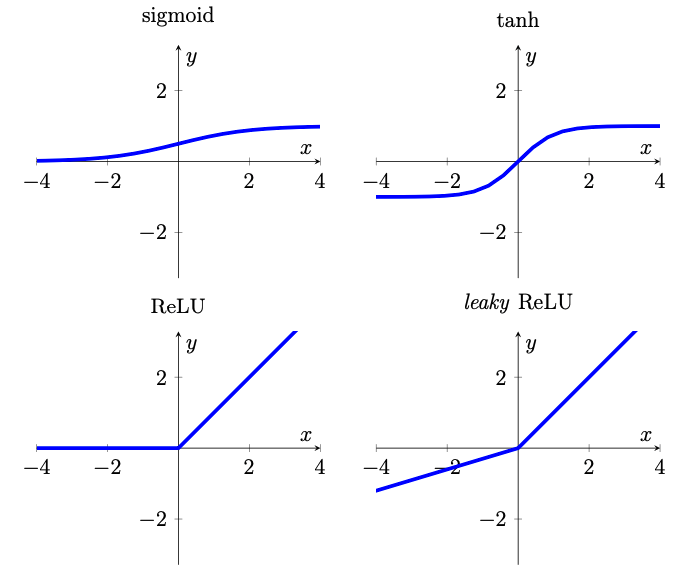
Ohne ins Detail zu gehen, seien hier die vier wichtigsten Aktivierungsfunktionen genannt. Die Steigung der Leaky- ReLU-Funktion wurde zur besseren Veranschaulichung übertrieben dargestellt (aus [1]).
Faltungsneuronale Netze
Bei der Bildanalyse werden dem neuronalen Netzwerk die Intensitätswerte jedes Pixels als Eingabe übergeben. In einem RGB-Bild gibt es drei Intensitäten für jede Farbe: Rot, Grün und Blau.
Um Speicherprobleme aufgrund der großen Bildgröße und der vielen zu verarbeitenden Parameter zu vermeiden, kann in diesem Fall ein kleineres Netzwerk verwendet werden. Jedes Pixel wird dann einzeln mittels Faltungen verarbeitet. Diese Faltungen dienen der Erstellung von Eigenschaftskarten . Diese können als mehrschichtige Bilder betrachtet werden: Jede Schicht repräsentiert eine Eigenschaft, die durch einen Faltungsfilter gewonnen wird.
Eigenschaftskarten sind klein und können von einem vollständig vernetzten Netzwerk ohne Speicherbeschränkungen verarbeitet werden. Dieser Modelltyp wird als Convolutional Neural Network ( CNN ) bezeichnet.
Faltungen
Wenn ein CNN ein neues Bild verarbeitet, weiß es nicht, welche Merkmale im Bild vorhanden sind oder wo sie sich befinden. Diese Netzwerke versuchen daher mithilfe von Filtern festzustellen, ob ein bestimmtes Merkmal im Bild vorhanden ist. Die mathematischen Verfahren, die für diese Operation verwendet werden, heißen Faltungen. Bei der Bildverarbeitung ist die Position des Pixels im Bild von grundlegender Bedeutung. Und das ist ein Glücksfall, denn diese Information wird von einer Faltungsschicht genutzt.
Das Faltungsfenster (oder der Faltungskern) ist eine kleine, oft quadratische Matrix. Seine Größe wird beim Netzwerkdesign festgelegt und beträgt häufig 3×3. Dieses Fenster „gleitet“ über die Eigenschaftskarte. An jeder Position wird das Produkt der Elemente des Faltungsfensters und des entsprechenden Abschnitts der Eigenschaftskarte berechnet (siehe Abbildung unten). Abschließend wird eine nichtlineare Funktion auf die Summe der Elemente der resultierenden Matrix angewendet.
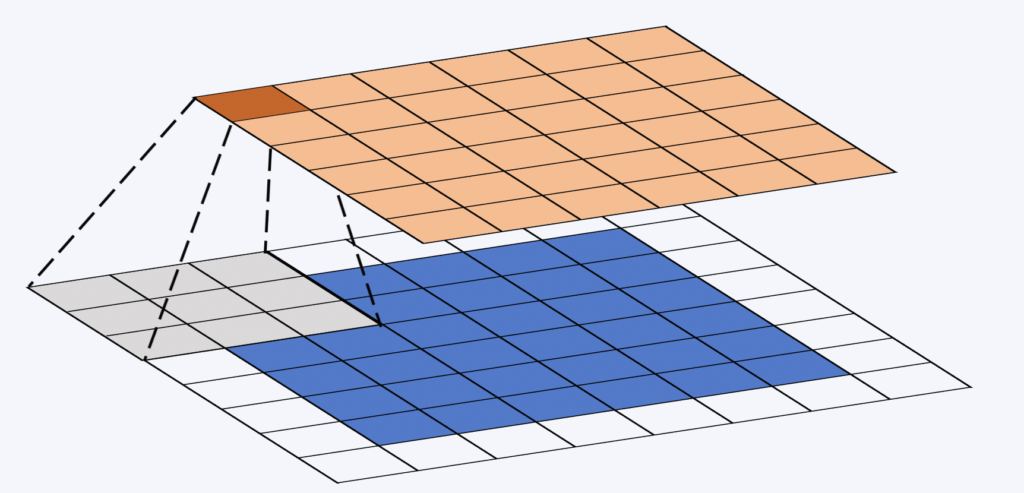
Während des Faltungsprozesses bleiben die Gewichte unverändert. So können wir die Rechenleistung moderner GPUs nutzen.
Pooling
Pooling ist eine Methode, um ein Bild zu nehmen und seine Größe zu reduzieren, während die wichtigsten darin enthaltenen Informationen erhalten bleiben.
Die gebräuchlichste Methode ist das sogenannte Max-Pooling. Dabei wird ein kleines Fenster über das gesamte Bild gezogen und in jedem Schritt der Maximalwert dieses Fensters ermittelt. Üblicherweise handelt es sich dabei um ein 2×2-Fenster bzw. eine 2×2-Matrix (siehe Abbildung unten).
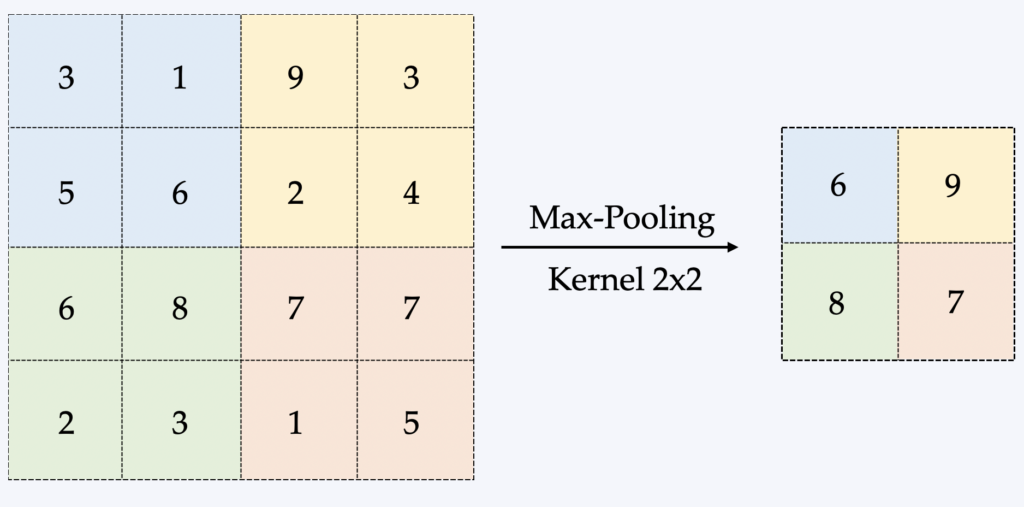
Der Hauptvorteil des Poolings besteht daher in der Reduzierung der im Speicher verarbeiteten Datenmenge, was beim Training von CNNs einen limitierenden Faktor darstellt. Die Backpropagation wird je nach Pooling-Methode unterschiedlich beeinflusst, worauf wir hier jedoch nicht näher eingehen werden.
Rezeptive Felder
Das rezeptive Feld bezeichnet einen Bildbereich, der dem Netzwerk als Eingabe dient. Durch die Vergrößerung des rezeptiven Feldes wird mehr Kontext für die Klassifizierung eines Ortes bereitgestellt. Dies ermöglicht auch die Erkennung größerer Objekte im Bild.
Pooling ist eine Methode zur Vergrößerung des rezeptiven Feldes eines Neurons. Die Aktivierungsfunktion modifiziert ebenfalls dieses effektive Feld, worüber wir in einem zukünftigen Artikel diskutieren werden.
Rückpropagation
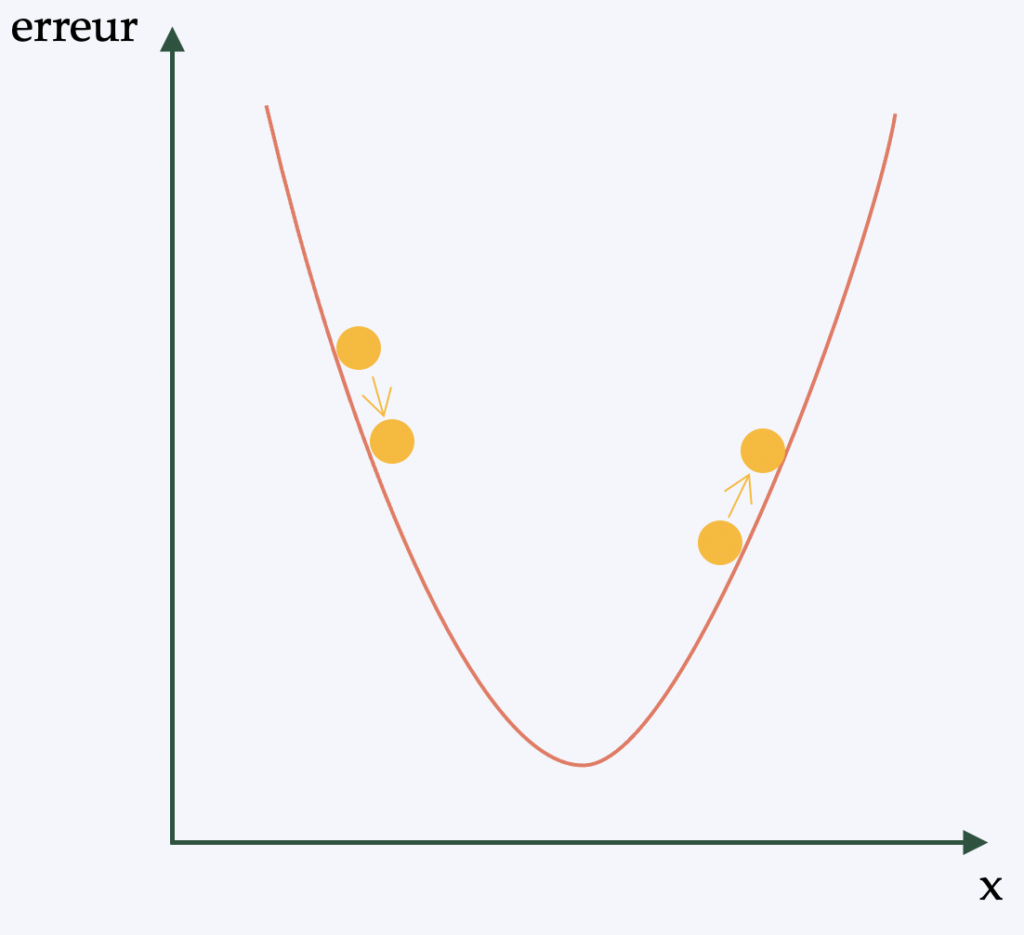
Vereinfacht ausgedrückt (und um eine etwas komplexere mathematische Beschreibung zu vermeiden), ist die Backpropagation der Algorithmus, der die Lernstrategie auf die Gewichte des neuronalen Netzes anwendet. Ziel ist es, eine Form des Gradientenabstiegs ( einen differenzierbaren Optimierungsalgorithmus ) auf das Netz anwenden zu können.
Tatsächlich, Für jedes vom CNN analysierte Bild wird ein „Score“ ermittelt. Die Anzahl der Fehler bei der Klassifizierung/Erkennung gibt die Qualität der Merkmale und Gewichtungen an. Diese werden anschließend angepasst, um den Fehler zu reduzieren – dies ist der Lernprozess. Unabhängig von der vorgenommenen Anpassung wird die Änderung beibehalten, wenn der Fehler dadurch sinkt. Dieser Prozess wird dann für jedes weitere annotierte Bild wiederholt.
Erfahren Sie mehr über überwachtes Deep Learning für die Objekterkennung in der Computer Vision.
In diesem Artikel haben wir lediglich die wenigen Hauptprinzipien des überwachten Deep Learning zur Objekterkennung in der Computer Vision beschrieben.
Wenn Sie KI in Ihr Computer-Vision-Projekt integrieren möchten, kontaktieren Sie uns – wir stellen Ihnen unser gesamtes Know-how zur Verfügung! Wir übernehmen die Erstellung des Datensatzes ( der Datenbank ), was ein umfangreiches Projekt darstellt. Wir sind in der Lage, aus Bildern oder Videos eine große Datenbank mit mehreren Tausend annotierten Bildern zu erstellen. Anschließend trainieren wir ein Modell, indem wir die passende neuronale Netzwerkarchitektur und -methodik auswählen.
Im nächsten Artikel stellen wir ein konkretes Beispiel für ein von Imasolia entwickeltes Objekterkennungsmodell vor. Bleiben Sie dran!