Il rilevamento degli oggetti nella visione computerizzata utilizza l'apprendimento profondo (o Apprendimento profondo una famiglia di modelli diapprendimento automatico descritti sotto forma di reti neurali organizzate in strati. In generale, tutti i modelli diapprendimento supervisionato per il rilevamento di oggetti in un'immagine sono reti neurali artificiali, utilizzate per il deep learning.
L'apprendimento profondo può essere supervisionato o non supervisionato, a seconda dei casi. Nel resto di questo articolo parleremo solo di apprendimento supervisionato. In quest'ultimo caso, i dati utilizzati per l'apprendimento supervisionato sono etichettati. In altre parole, si conosce il risultato che il modello deve ottenere. E questo viene fatto per ogni esempio utilizzato nel processo di apprendimento. L'obiettivo finale è imparare ad associare a ogni esempio la giustaetichetta.
Prendetevi qualche minuto e parliamo dei principi fondamentali dell'apprendimento profondo supervisionato per il rilevamento degli oggetti! Si noti che mi sono imposto di non addentrarmi in una descrizione matematica del Deep Learning. Questo articolo è quindi pensato per essere accessibile a tutti.

Apprendimento profondo supervisionato per il rilevamento di oggetti in computer vision
Principi generali del rilevamento degli oggetti nella visione artificiale
Una rete neurale artificiale è un modello di apprendimento automatico composto da unità di calcolo chiamate neuroni. Un neurone calcola una somma ponderata degli ingressi e applica una funzione non lineare al risultato di questa somma. Si tratta della funzione di attivazione, sulla quale torneremo più avanti.
Spesso l'uscita di un neurone viene trasmessa all'ingresso di uno o più neuroni (a seconda del numero di strati), fino a raggiungere l'uscita della rete. A volte si può utilizzare anche una rete neurale ricorrente. In questo caso, l'uscita di un neurone può essere utilizzata come ingresso per lo stesso neurone.
L'apprendimento di una rete neurale comporta l'ottimizzazione della ponderazione di ogni somma. In questo modo, i pesi diventano i parametri della rete. Per ottimizzare i pesi, è necessario utilizzare un algoritmo di back-propagation per minimizzare l'errore tra la previsione e l'etichetta data in ingresso.
Come funziona un neurone
Analogamente a un neurone biologico, un neurone artificiale riceve segnali di ingresso da altri neuroni. Le sinapsi sono modellate da pesi assegnati ai valori di ingresso.
I neuroni non sono sempre attivi. Un valore elevato del peso provoca l'eccitazione del neurone. Al contrario, se il peso è negativo, l'ingresso avrà un'azione inibitoria. Se la somma ponderata di questi ingressi supera una certa soglia, il neurone si attiva. È la funzione di attivazione a decidere la soglia. Il risultato della funzione di attivazione viene poi trasmesso ai neuroni successivi.
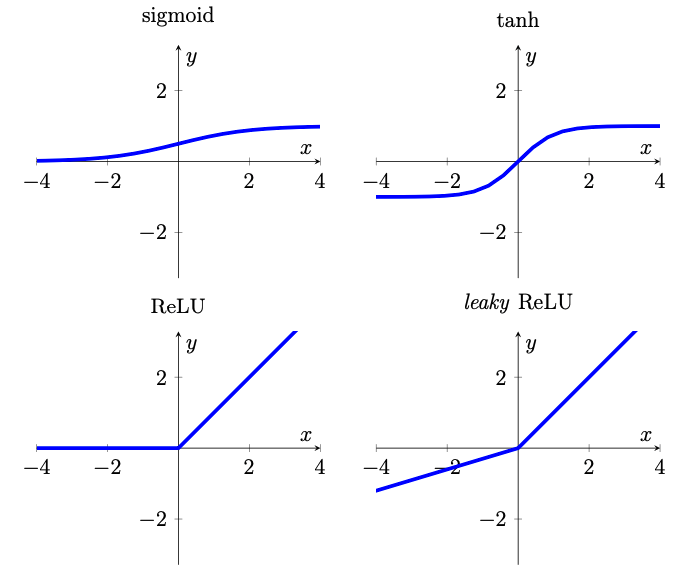
Senza entrare nei dettagli, ecco le quattro principali funzioni di attivazione. La pendenza della ReLu leaky è stata esagerata per una migliore visibilità (da [1]).
Reti convoluzionali
Quando si analizza un'immagine, le proprietà date in ingresso alla rete neurale sono i valori di intensità di ciascun pixel. Per un'immagine RGB, ci sono tre intensità per ogni colore: rosso, verde e blu.
In questo caso, per evitare problemi di memoria dovuti alle grandi dimensioni delle immagini e al numero di parametri da elaborare, possiamo utilizzare una rete di dimensioni ridotte. Ogni pixel viene elaborato individualmente utilizzando le convoluzioni. Queste vengono utilizzate per produrre le mappe di proprietà. Possiamo considerarle come immagini multistrato: ogni strato è una proprietà ottenuta con un filtro di convoluzione.
Le mappe di proprietà hanno dimensioni ridotte e possono essere elaborate da una rete completamente connessa senza problemi di memoria. Questo tipo di modello è noto come rete neurale convoluzionale(CNN ).
Convoluzioni
Quando una rete CNN elabora una nuova immagine, non sa quali caratteristiche siano presenti nell'immagine e dove si trovino. Queste reti cercano quindi di scoprire se una caratteristica dell'immagine è presente utilizzando un filtro. La matematica utilizzata per eseguire questa operazione si chiama convoluzione. Quando si elabora un'immagine, la posizione del pixel nell'immagine è di fondamentale importanza. È bene che questa informazione venga sfruttata da uno strato di convoluzione.
La finestra di convoluzione (o kernel) è spesso una piccola matrice quadrata. La sua dimensione è fissata al momento della progettazione della rete ed è spesso 3×3. Questa finestra "scorre" sulla mappa delle proprietà. In ogni punto si calcola il prodotto di termine tra la finestra di convoluzione e la parte della mappa di proprietà su cui si trova (vedi figura sotto). Infine, si applica una funzione non lineare alla somma degli elementi della matrice risultante.
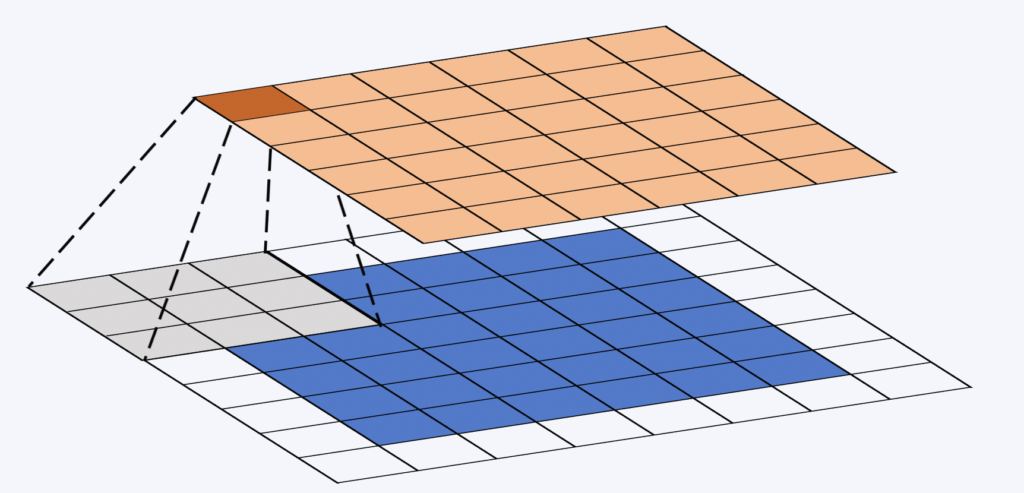
Durante il processo di convoluzione, i pesi sono invarianti. In questo modo è possibile sfruttare la potenza di calcolo delle moderne GPU.
Messa in comune
Il raggruppamento è un metodo per prendere un'immagine e ridurne le dimensioni preservando le informazioni più importanti che contiene.
La forma più comune è quella chiamata Max-Pooling, che consiste nel trascinare una piccola finestra su tutte le parti dell'immagine e prendere il valore massimo di questa finestra a ogni passo. In genere si tratta di una finestra/matrice di dimensioni 2×2 (si veda l'illustrazione seguente).
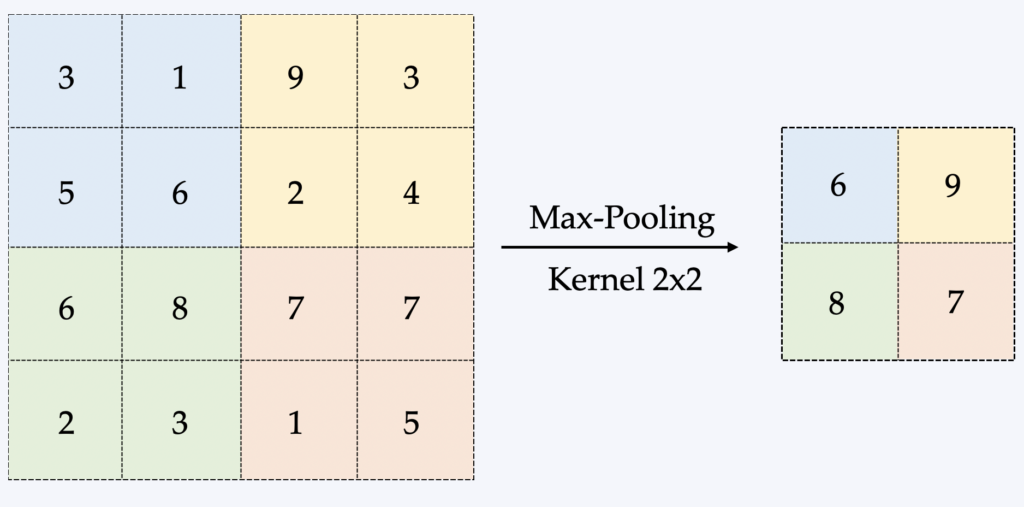
Il vantaggio principale del pooling è quindi quello di ridurre la dimensione dei dati elaborati in memoria, che è un fattore limitante nell'apprendimento di una CNN. La backpropagation è influenzata in modo diverso dal pooling, ma non entreremo nei dettagli in questa sede.
Campi ricettivi
Il campo recettivo designa una regione dell'immagine passata come input alla rete. L'aumento del campo recettivo fornisce un contesto più ampio per la classificazione di un luogo. Inoltre, consente di rilevare oggetti più grandi all'interno di un'immagine.
Il pooling è un metodo per aumentare il campo recettivo di un neurone. Anche la funzione di attivazione modifica questo campo recettivo, e di questo potremo parlare in un prossimo articolo.
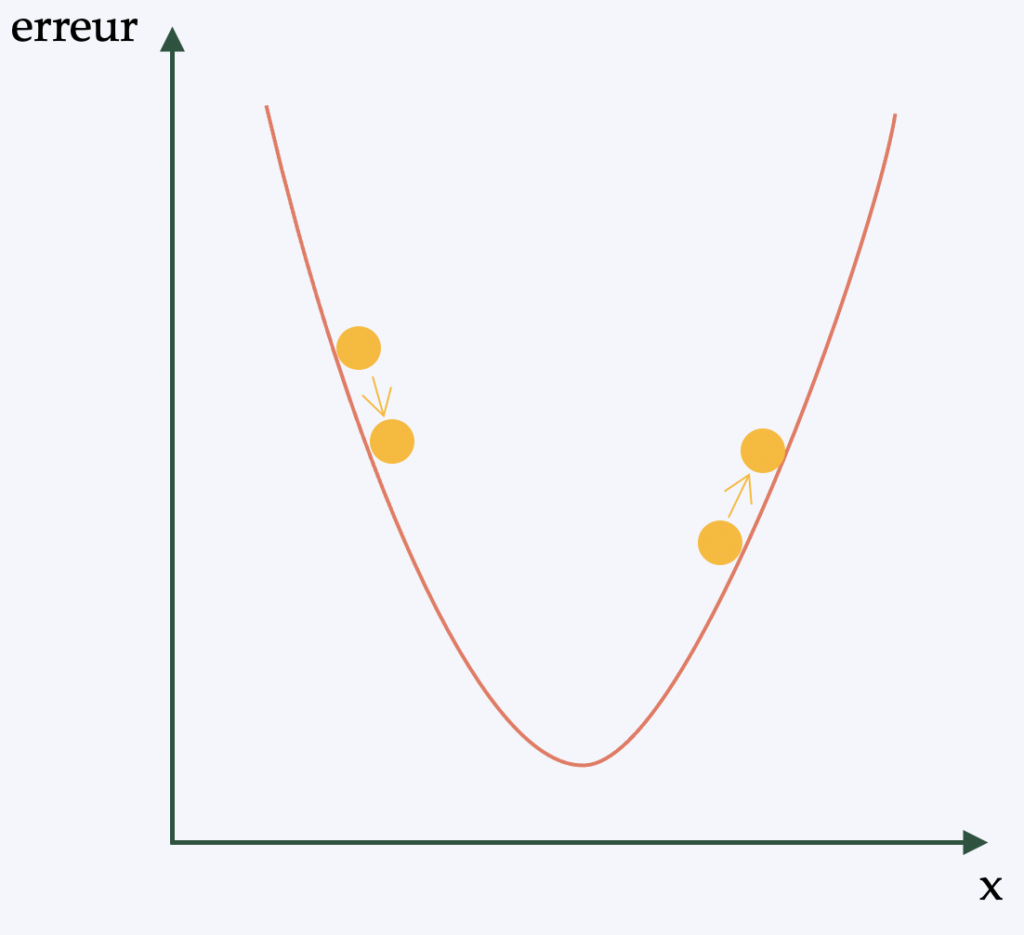
Retropropagazione
In termini semplici (e per evitare una descrizione matematica piuttosto complessa), la retropropagazione è l'algoritmo utilizzato per applicare la politica di apprendimento ai pesi della rete neurale. L'obiettivo è quello di poter applicare alla rete una forma di discesa del gradiente(algoritmo di ottimizzazione differenziabile).
In effetti, ci dà un "punteggio" per ogni immagine analizzata dalla CNN. La qualità delle caratteristiche e dei pesi è determinata dal numero di errori commessi nella classificazione/rilevazione. Le caratteristiche e i pesi vengono quindi aggiustati per ridurre l'errore, il che è lo scopo dell'apprendimento. Qualunque sia la regolazione effettuata, se l'errore si riduce, la regolazione viene mantenuta. Questo processo viene poi ripetuto con tutte le altre immagini che hanno un'etichetta.
Per saperne di più sull'apprendimento profondo supervisionato per il rilevamento degli oggetti nella computer vision
In questo articolo abbiamo semplicemente descritto i principi principali del deep learning supervisionato per il rilevamento degli oggetti nella computer vision.
Se volete incorporare l'IA nel vostro progetto di visione, contattateci e metteremo tutta la nostra esperienza al vostro servizio! Gestiamo la creazione del dataset(database), che rappresenta una quantità significativa di lavoro. Siamo in grado di creare un grande database di immagini o video (con diverse migliaia di immagini annotate). Poi addestriamo un modello scegliendo la giusta architettura di rete neurale e utilizzando la giusta metodologia.
Nel prossimo articolo, presenteremo un caso di studio di un modello di rilevamento di oggetti sviluppato da Imasolia. Restate connessi!