La détection d’objets en computer vision utilise l’apprentissage profond (ou Deep Learning en Anglais) qui regroupe une famille de modèles d’apprentissage automatique, décrits sous forme de réseaux de neurones organisés en couches. Généralement, l’ensemble des modèles d’apprentissage supervisés pour la détection d’objets dans une image sont des réseaux de neurones artificiels, utilisés pour faire de l’apprentissage profond.
L’apprentissage profond peut-être supervisé ou non supervisé en fonction des cas. Dans la suite de cet article nous parlerons uniquement d’apprentissage supervisé. Dans ce dernier cas, les données utilisées pour l’apprentissage supervisé sont étiquetées. C’est-à-dire que l’on connais le résultat auquel le modèle doit parvenir. Et ceci pour chaque exemple utilisé lors de l’apprentissage. Le but ultime est d’apprendre à associer chaque exemple à une étiquette (label) juste.
Prenez quelques minutes et posons ensemble les grands principes de l’apprentissage profond supervisé pour la détection d’objets ! Veuillez noter que j’ai mis un point d’honneur à ne pas entrer dans une description mathématique du Deep Learning. Cet article se veut donc accessible à tous.

L’apprentissage profond supervisé pour la détection d’objets en computer vision
Principes généraux de a détection d’objets en computer vision
Un réseau de neurones artificiels est un modèle d’apprentissage automatique constitué d’unités de calculs appelés neurones. Un neurone calcule une somme pondérée des entrées et applique une fonction non linéaire au résultat de cette somme. Il s’agit de la fonction d’activation, on y reviendra plus tard.
Souvent, la sortie d’un neurone est transmise en entrée d’un ou plusieurs neurones (en fonction du nombre de couches), jusqu’à atteindre la sortie du réseau. Parfois on peut aussi utiliser un réseau de neurones récurrent. Dans cette situation, la sortie d’un neurone peut être utilisée en entrée de ce même neurone.
L’apprentissage d’un réseau de neurones consiste à optimiser la pondération de chaque somme. Ainsi, les poids deviennent les paramètres du réseau. Pour optimiser les poids, il faut utiliser un algorithme de rétro-propagation pour minimiser l’erreur entre la prédiction et l’étiquette donnée en entré.
Fonctionnement d’un neurone
De manière analogique à un neurone biologique, un neurone artificiel reçoit des signaux d’autres neurones en entrée. Les synapses sont modélisées par des poids attribués aux valeurs d’entrée.
Les neurones ne sont pas toujours actifs. En effet, une valeur de poids élevée provoquera l’excitation du neurone. A l’inverse, si le poids est négatif, alors l’entrée aura une action dite inhibitrice. Si la somme pondérée de ces entrées dépasse un certain seuil, le neurone est activé. C’est la fonction d’activation qui a pour rôle de décider du seuil. Ainsi, le résultat issu de la fonction d’activation est ensuite transmis au neurones suivants.
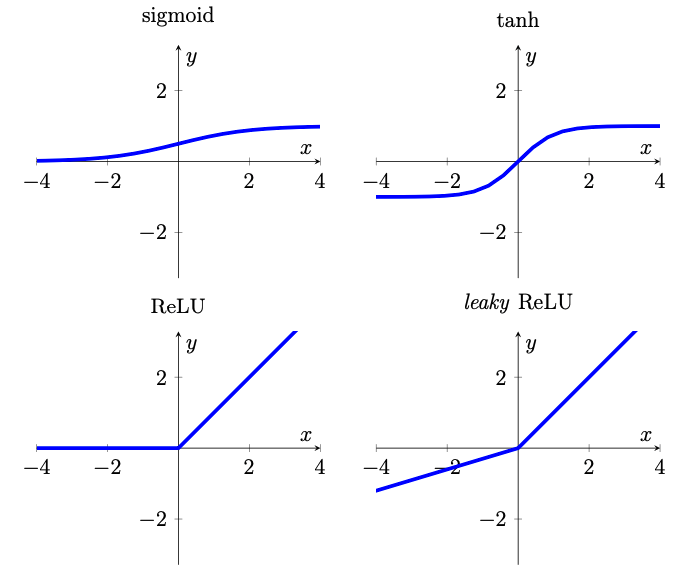
Sans entrer dans les détails, voici ci-dessous les quatre principales fonctions d’activation. La pente du leaky ReLu a été exagérée pour plus de visibilité (d’après [1]).
Réseaux convolutifs
Quand on analyse une image, les propriétés données en entrée du réseau de neurones sont les valeurs d’intensité de chaque pixel. Pour une image RGB, il y a trois intensités pour chaque couleur : le rouge, le vert et le bleu.
Dans ce cas, et pour éviter les problèmes de mémoires à cause de la grande taille des images et le nombre de paramètres à traiter nous pouvons utiliser un réseau de taille réduite. Ainsi, on traite chaque pixel individuellement à l’aide de convolutions. Ce sont-elles qui servent à fabriquer les cartes de propriétés. On peut voir cela comme des images multi-couches : chaque couche est une propriété obtenue grâce à un filtre de convolution.
Les cartes de propriétés sont de tailles réduites et peuvent être traitées par un réseau entièrement connecté sans soucis de mémoire. On appelle ce type de modèle, un réseau de neurones convolutifs (CNN en anglais, pour Convolutional Neural Network).
Convolutions
Lorsque qu’un réseau CNN traite une nouvelle image, il ne sait pas quelles caractéristiques sont présentes dans l’image et l’endroit où elles pourraient être. Ces réseaux cherchent donc à savoir si une caractéristique dans l’image est présente à l’aide de filtrage. Les mathématiques utilisées pour réaliser cette opération sont appelés convolutions. Lorsque l’on traite une image, la position du pixel dans cette dernière a une importance fondamentale. Et ça tombe bien puisque cette information est exploitée par une couche de convolution.
La fenêtre (ou noyau) de convolution, est une matrice souvent carrée et de petite taille. Sa taille est fixée à la conception du réseau et a souvent une taille de 3×3. Cette fenêtre “glisse” sur la carte de propriété. A chaque emplacement on calcule le produit terme à terme entre la fenêtre de convolution et la partie de la carte de propriétés sur laquelle elle se trouve (voir l’illustration ci-dessous). Enfin, une fonction non linéaire est appliquée sur la somme des éléments de la matrice résultante.
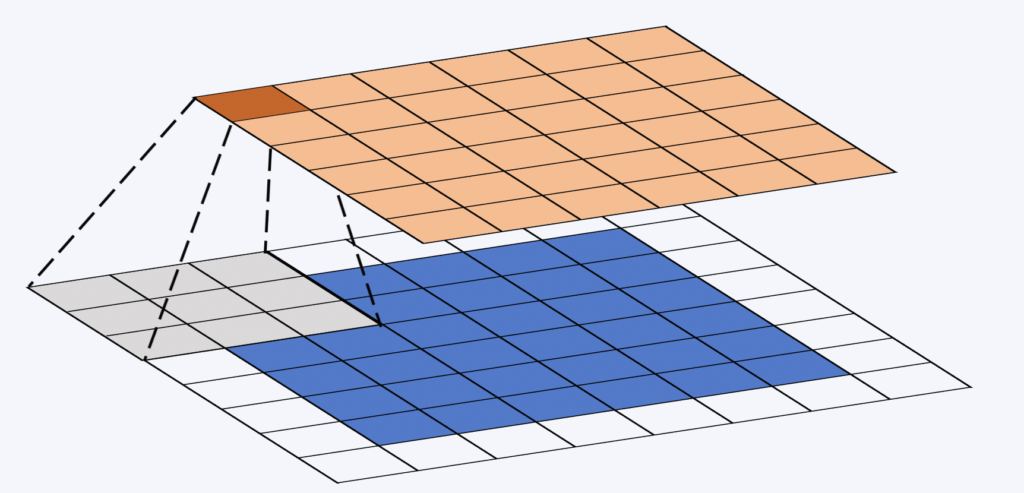
Pendant le processus de convolution, les poids sont invariants. C’est ainsi que nous pouvons utiliser la puissance de calcul des GPUs modernes.
Pooling
Le pooling est une méthode permettant de prendre une image et d’en réduire la taille tout en préservant les informations les plus importantes qu’elle contient.
La forme la plus courante s’appelle le Max-Pooling consistant à faire glisser une petite fenêtre sur toutes les parties de l’image et de prendre la valeur maximum de cette fenêtre à chaque pas. Il s’agit généralement d’une fenêtre/matrice de taille 2×2 (voir l’illustration ci-dessous).
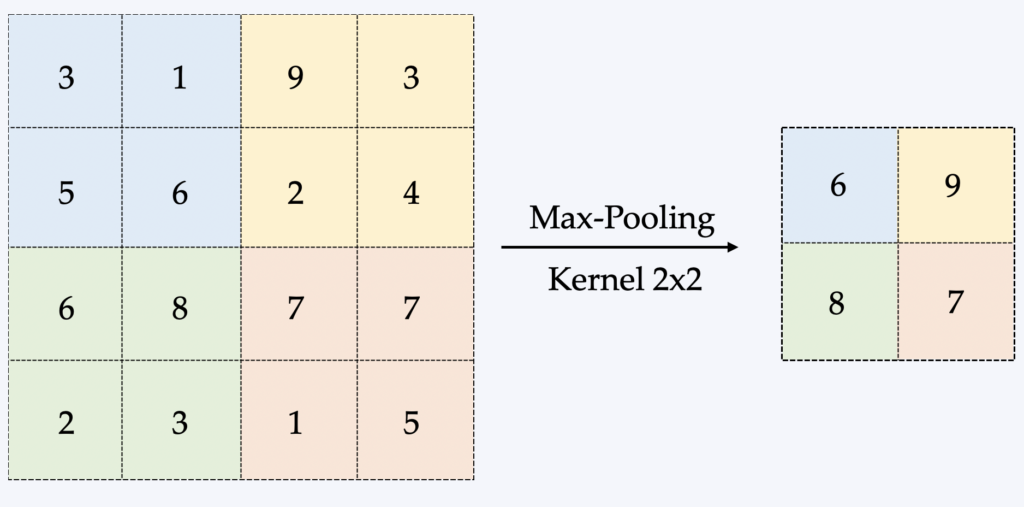
L’avantage majeur du pooling est donc de réduire la taille des données traitées en mémoire, qui est un facteur limitant dans l’apprentissage d’un CNN. La rétro-propagation est affectée différemment en fonction du pooling mais on ne rentrera pas dans le détail ici.
Champs réceptif
Le champ réceptif désigne une région de l’image passée en entrée du réseau. Augmenter le champ réceptif permet de donner plus de contexte pour classifier une localité. Cela permettra aussi de détecter des objets de plus grande dimension au sein d’une image.
Le pooling est une méthode augmentant le champ réceptif d’un neurone. La fonction d’activation modifie également ce champ effectif, et nous en parlerons peut-être dans un prochain article.
Rétro propagation
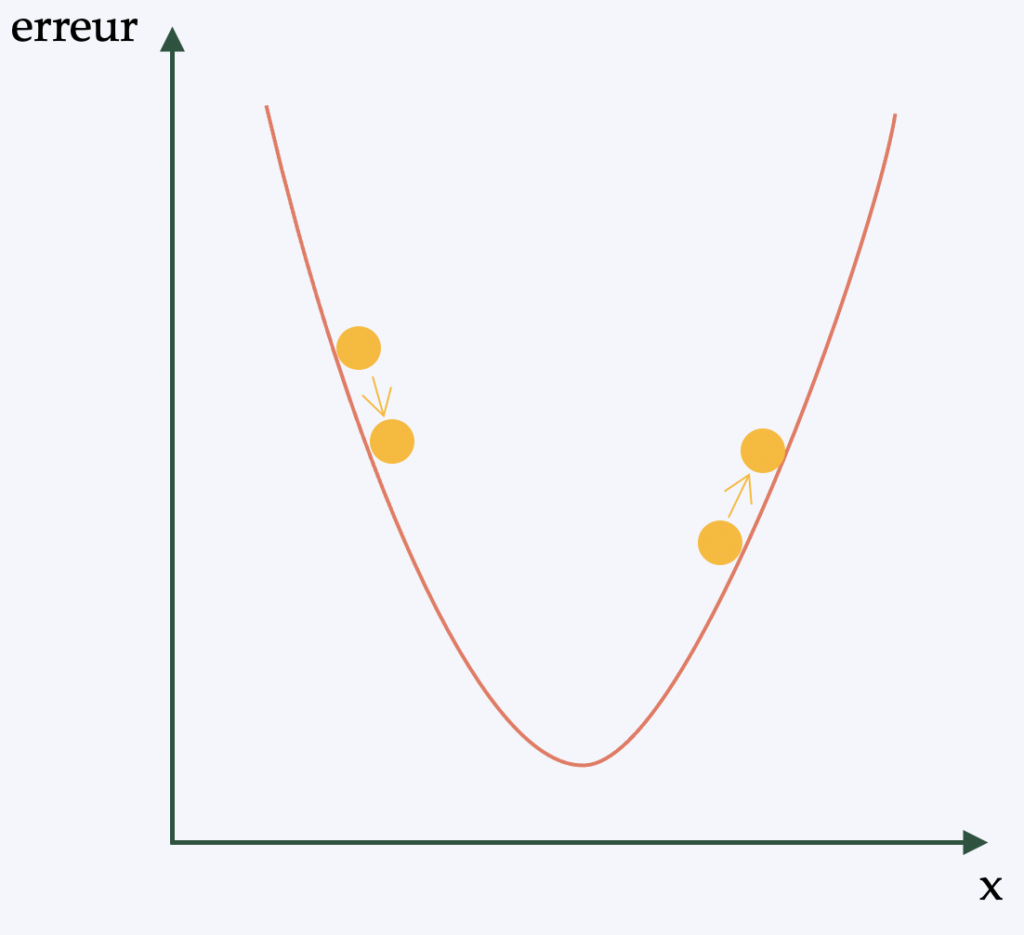
Pour faire simple, (et dans le but d’éviter d’entrer dans une description mathématique un peu complexe), la rétro-propagation est l’algorithme permettant d’appliquer la politique d’apprentissage aux poids du réseau de neurones. Le but est de pouvoir appliquer une forme de descente de gradient (algorithme d’optimisation différentiable) au réseau.
Enfaite, pour chaque image analysée par le CNN on obtient une “note”. On est renseigné sur la qualité de nos caractéristiques et de nos poids par le nombre d’erreurs que l’on fait dans notre classification/détection. Les caractéristiques et poids sont ensuite ajustées de façons à réduire l’erreur et c’est en cela que consiste l’apprentissage. Quel que soit l’ajustement fait, si l’erreur diminue, l’ajustement est conservé. Ce processus est ensuite répété avec chacune des autres images qui ont un label.
En savoir plus sur l’apprentissage profond supervisé pour la détection d’objets en computer vision
Dans cet article nous avons décrit simplement les quelques grands principes de l’apprentissage profond supervisé pour la détection d’objets en computer vision.
Si vous souhaitez embarquez de l’IA dans votre projet de vision, vous pouvez nous contacter et nous mettrons tout notre savoir faire à votre service ! Nous gérons la création du jeu de données (base de données) qui représente un travail important. Nous sommes capables de créer une grande base de données à partir d’images ou de vidéos (avec plusieurs milliers d’images annotées). Nous entrainons ensuite un modèle en choisissant la bonne architecture du réseau de neurones et avec la bonne méthodologie.
Dans le prochain article, nous présenterons un cas concret d’un modèle de détection d’objets développé par Imasolia. Restez connecté !